


新智元报道
编辑:定慧 好困
【新智元导读】Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。
AI,到处都是AI!

早上起来,脑子里突然萦绕起一个旋律,于是便对着AI随便哼了几句让它找出来是哪首歌;到公司之后,打开电脑里的AI,开始准备关于昨天工作的汇报。
只见你熟练地敲入:「根据以下这些文档,写一份总结,要专业、有逻辑、内容简洁」。
没过多久,一份涵盖了各项要点,稍微修改一下即可提交的材料就新鲜出炉了。
但你有没有想过,AI是如何理解人类定义的「专业」和「简洁」的?
为什么这么抽象的词,它能如此轻松地get到呢?
之所以AI能应对我们的百般刁难,是因为这背后有一个我们平时看不到的功臣——「奖励模型」(Reward Model)。
所谓奖励模型,就像一个「人类偏好感应器」——它能学会你喜欢什么样的输出,打分并反馈给AI。
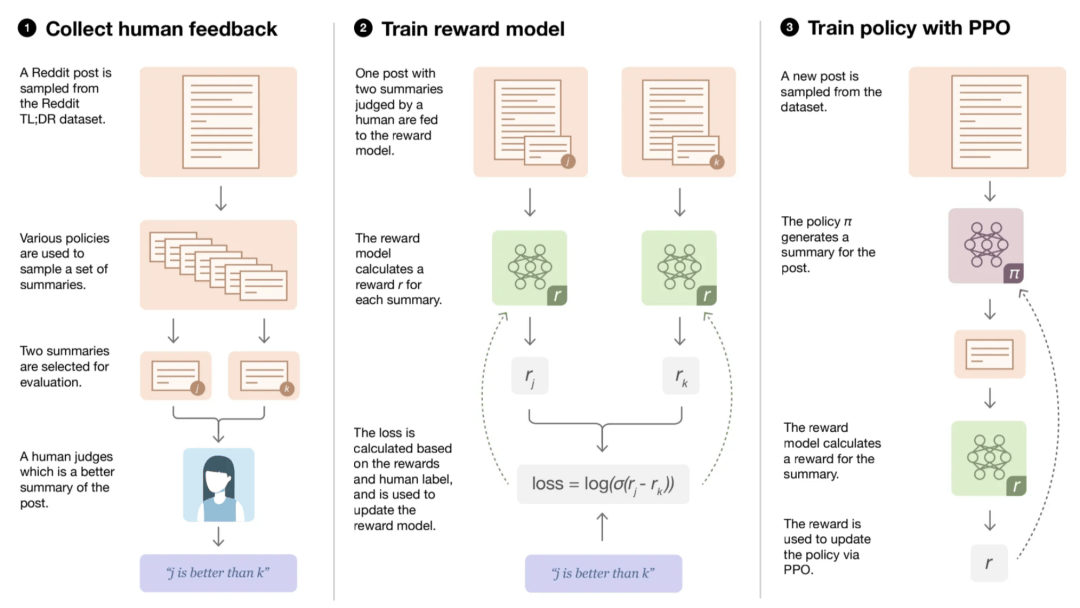
众所周知,LLM在训练中会用到RLHF,也就是「基于人类反馈的强化学习」。
但实际上,AI学习的并不是你的直接评价,而是先学会模拟你的打分标准(RM),再通过强化学习学着讨好它。
也就是说,AI是在向「你的大脑裁判」请教该怎么干活。
在这个过程中扮演着关键作用的,便是奖励模型。
OpenAI在论文中曾经证明,只要拥有一个学会人类偏好的奖励模型,小规模的1.3B模型也能在人工评测上击败175B的巨无霸GPT-3。

论文地址:https://arxiv.org/pdf/2203.02155
正因如此,奖励模型也被称为「通用智能的基石」。
它的好坏,也就直接决定了AI到底能不能真的理解了人类的偏好。
然而,即使是当前最先进的开源奖励模型,在大多数主流测评中表现得也不够理想。尤其是让模型能够在多维度、多层次体现人类偏好。
毕竟人类还是太过于复杂了,很难单一的量化。
「如何才能捕捉到人类偏好中细致而复杂的特征」,可以说是奖励模型的「终极使命」了。
自诞生之初,Skywork-Reward系列便聚焦于奖励模型的核心使命——理解并对齐人类偏好。

2024年9月发布的V1版本开源以来,已在Hugging Face平台累计获得75万次下载,充分验证了该系列在开源社区的实际价值与广泛应用。
经过9个月的持续优化后,Skywork-Reward-V2今天重磅登场。

技术报告:https://arxiv.org/abs/2507.01352
GitHub:https://github.com/SkyworkAI/Skywork-Reward-V2
Hugging Face:https://huggingface.co/collections/Skywork/skywork-reward-v2-685cc86ce5d9c9e4be500c84
Skywork-Reward-V2系列包含8个基于不同基座模型和不同大小的奖励模型,参数从6亿到80亿。
Skywork-Reward-V2在多个能力维度上都能更好的理解人类,对齐人类,包括对人类偏好的通用对齐、客观正确性、安全性、风格偏差的抵抗能力,以及best-of-N扩展能力。
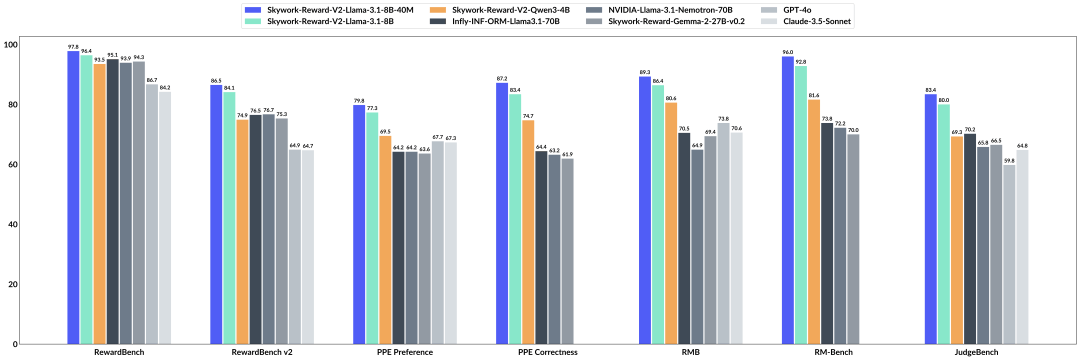
实测后表明,该系列模型在七个主流奖励模型评测基准上都刷新了SOTA。
Skywork-Reward-V2实测
话不多说,下面我们来就看看,Skywork-Reward-V2-Llama-3.1-8B在极为困难的RewardBench v2测试集上的实际预测结果,到底如何。
实例1:Skywork-Reward-V2-Llama-3.1-8B拥有判断模型回复是否精确循序指令的能力。
实例2:Skywork-Reward-V2-Llama-3.1-8B能够选择最安全和稳妥的回答,并对带有泄露隐私的模型回复给予低分。
实例3:Skywork-Reward-V2-Llama-3.1-8B在一定程度上能够识别细微的事实性错误。
为何「死磕」奖励模型?
目前不少奖励模型都是「应试型学霸」——在特定基准任务表现非常好,但实际靠的是「死记硬背」。
对特定训练集内的偏好精准拿捏,可一旦换个领域就抓瞎,题型一换、知识点打乱,就完全失去了判断力。

图左丨31个顶尖开源奖励模型在RewardBench上的能力对比;图右丨分数的相关性——很多模型在RewardBench上性能提升后,在其他Benchmark上成绩却「原地踏步」,这可能意味着过拟合现象。
为了克服这种「过拟合」和现象,近期兴起了一种GRM(Generative Reward Model)生成式奖励模型。
比如DeepSeek于2025年4月3日首次发布的论文,但这种提升比较有限。
论文地址:https://arxiv.org/pdf/2504.02495
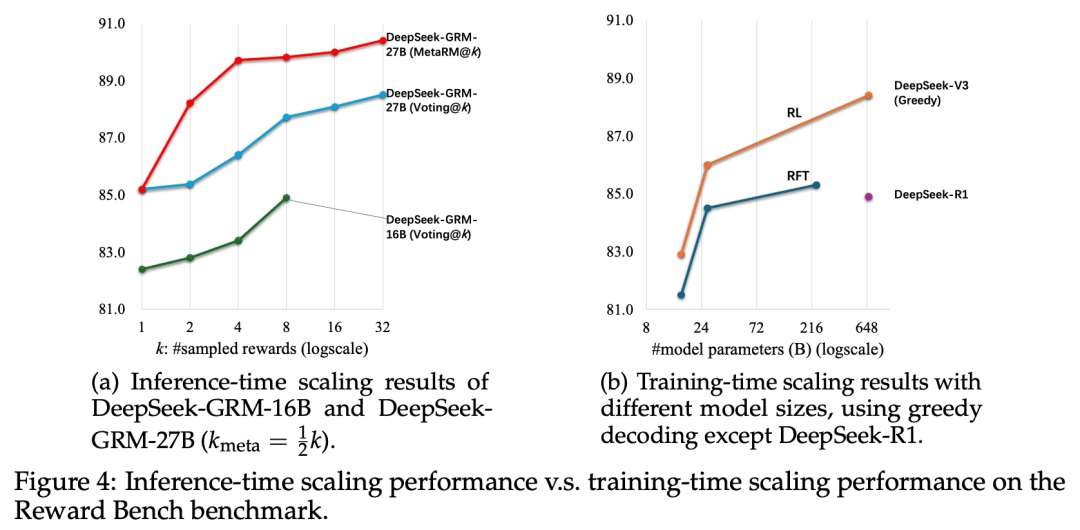
与此同时,以OpenAI的o系列模型和DeepSeek-R1为代表的模型推动了「可验证奖励强化学习」(Reinforcement Learning with Verifiable Reward, RLVR)方法的发展。

论文地址:https://cdn.openai.com/prover-verifier-games-improve-legibility-of-llm-outputs/legibility.pdf?utm_source=chatgpt.com
然而,由于人类的偏好在本质上是复杂、细致,且难以捕捉的。
因此,使用这些覆盖范围有限、标签生成方式较为机械,或缺乏严格质量控制的偏好数据所训练的奖励模型,在优化开放式、主观性较强的任务时就变得会十分「脆弱」。
那么,如何才能更好捕捉人类偏好中那些复杂、难以琢磨的特性,如何让RM更懂得人类,帮助训练与人类更加对齐的模型呢?
巧妙构建千万级人类偏好数据
得益于第一代模型在数据优化方面的经验,团队在V2奖励模型的研发中,决定引入更加多样且规模更大的真实人类偏好数据。
这样就可以在提升数据规模的同时兼顾数据质量,从而让奖励模型「更懂人类偏好」。
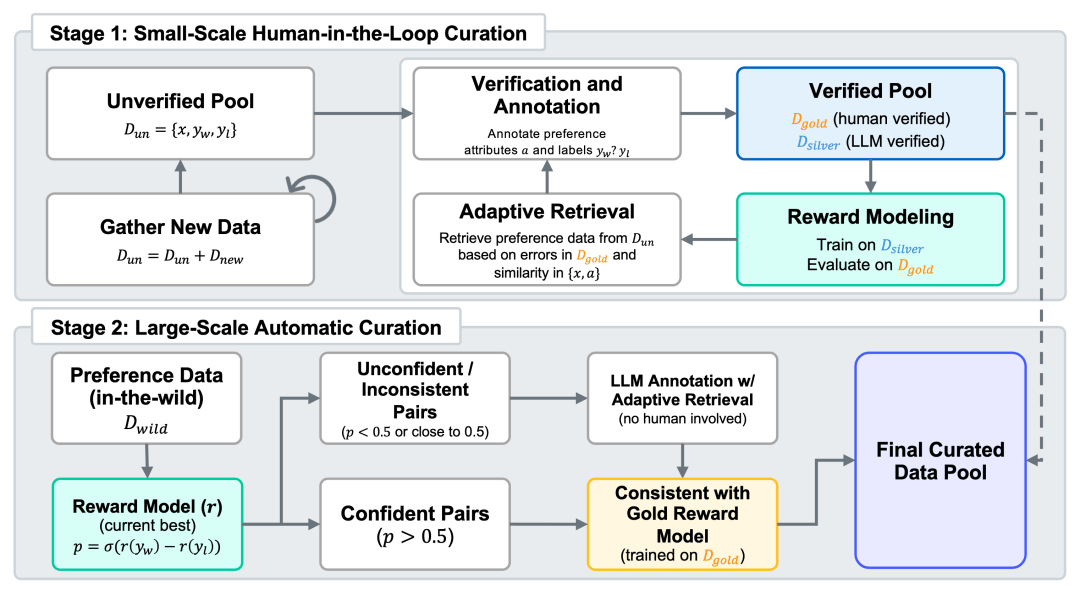
为此,迄今为止规模最大,总计包含4,000万对偏好样本的偏好混合数据集——Skywork-SynPref-40M诞生了。
其核心创新,在于一条「人机协同、两阶段迭代」的数据筛选流水线。
阶段一:人工构建小规模高质量偏好数据
首先,团队构建了一个未经验证的初始偏好池,并借助LLM生成与偏好相关的辅助属性,如任务类型、客观性、争议性等。
在此基础上,人工标注者依照一套严格的验证协议,并借助外部工具与先进的大语言模型,对部分数据进行精细审核,最终构建出一个小规模但高质量的「金标准」数据集,作为后续数据生成与模型评估的依据。
随后,Skywork以金标准数据中的偏好标签为引导,结合LLM大规模生成高质量的「银标准」数据,从而实现数据量的扩展。
团队还进行了多轮迭代优化:每一轮中,训练奖励模型并根据其在金标准数据上的表现,识别模型的薄弱环节;
再通过检索相似样本并利用多模型一致性机制自动标注,进一步扩展和增强银标准数据。
这一人机协同的闭环流程持续迭代,有效提升了奖励模型对偏好的理解与判别能力。
阶段二:全自动扩展大规模偏好数据
在获得初步高质量模型之后,第二阶段转向自动化的大规模数据扩展。
此阶段不再依赖人工审核,而是采用训练完成的奖励模型执行一致性过滤:
1. 若某个样本的标签与当前最优模型预测不一致,或模型置信度较低,则调用LLM重新自动标注;
2. 若样本标签与「金模型」(即仅使用人工数据训练的模型)预测一致,且获得当前模型或LLM支持,则可直接通过筛选。
借助该机制,团队从原始的4,000万样本中成功筛选出2,600万条精选数据,在极大减少人工标注负担的同时,实现了偏好数据在规模与质量之间的良好平衡。
小尺寸,大性能
准备好数据,下一步就是训练了。
相比上一代Skywork-Reward,全新发布的Skywork-Reward-V2系列提供了基于Qwen3和LLaMA 3系列模型训练的8个奖励模型,参数规模覆盖从6亿至80亿。
在RewardBench v1/v2、PPE Preference & Correctness、RMB、RM-Bench、JudgeBench等共七个主流奖励模型评估基准上
Skywork-Reward-V2系列全面达到了SOTA。
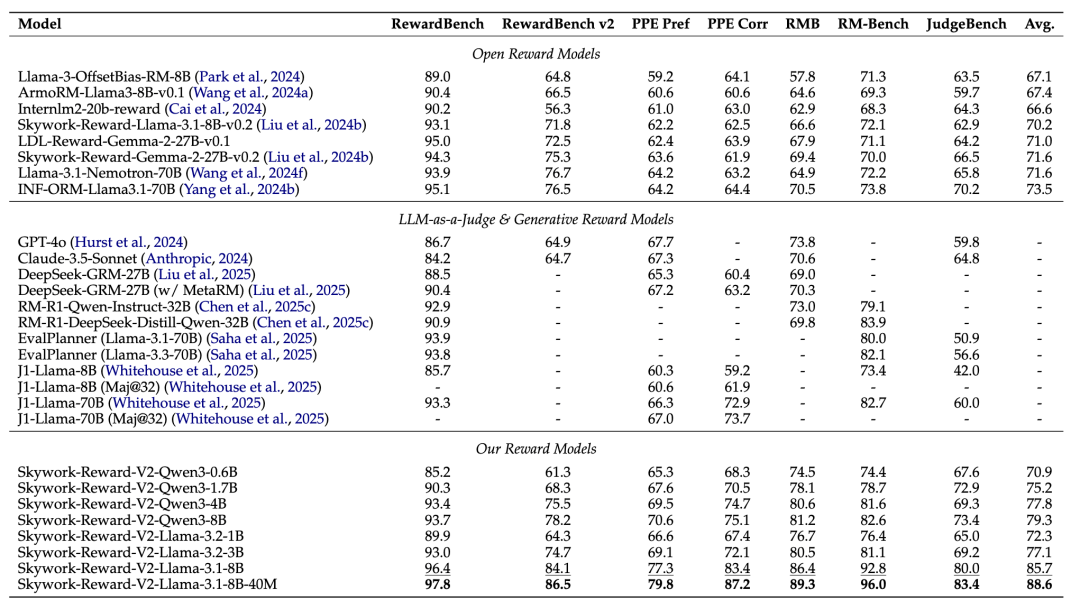
挑战模型规模限制
新一代模型可以用0.6B媲美上一代模型的27B水准。
最小模型Skywork-Reward-V2-Qwen3-0.6B,其整体性能已几乎达到上一代最强模型Skywork-Reward-Gemma-2-27B-v0.2的平均水平。
更进一步,Skywork-Reward-V2-Qwen3-1.7B在平均性能上已超越当前开源奖励模型的SOTA——INF-ORM-Llama3.1-70B。
而最大规模的Skywork-Reward-V2-Llama-3.1-8B,在所有主流基准测试中实现了全面超越,成为当前整体表现最优的开源奖励模型。
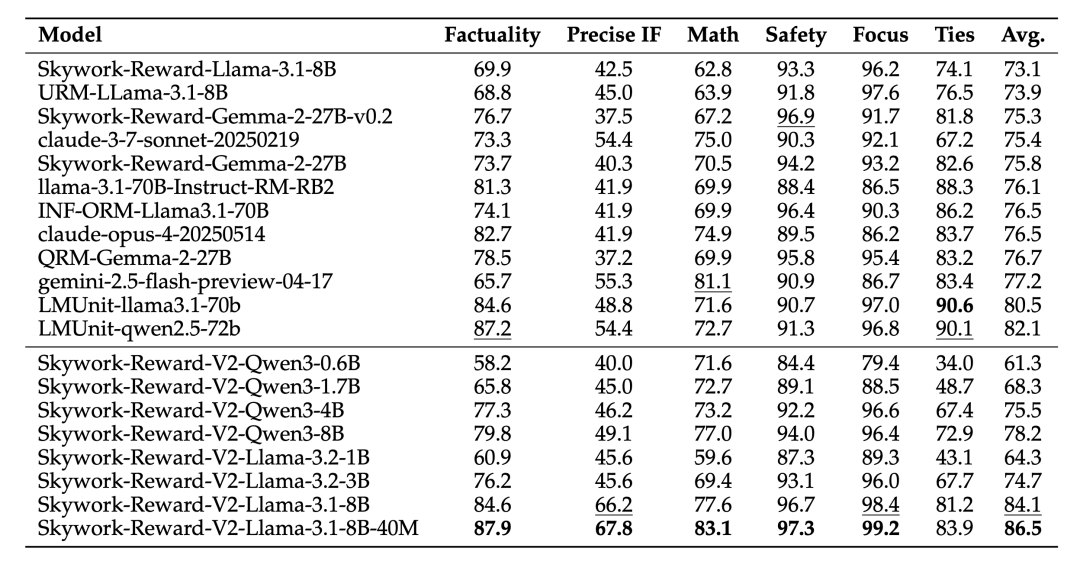
Skywork-Reward-V2系列在RewardBench v2评测集上的表现
广泛覆盖人类偏好
在通用偏好评估基准(如RewardBench)上,Skywork-Reward-V2系列优于多个参数更大的模型(如70B)及最新的生成型奖励模型(GRM),进一步验证了高质量数据的重要性。
在客观正确性评估方面(如JudgeBench和PPE Correctness),尽管整体略逊于少数专注于推理与编程的闭源模型(如OpenAI的o系列),但在知识密集型任务中表现突出,超越了所有其他开源模型。
此外,Skywork-Reward-V2在多项高级能力评估中均取得领先成绩,展现了出色的泛化能力与实用性。包括:
-
Best-of-N(BoN)任务
-
偏见抵抗能力测试(RM-Bench)
-
复杂指令理解
-
真实性判断(RewardBench v2)
Best-of-N(BoN)任务
偏见抵抗能力测试(RM-Bench)
复杂指令理解
真实性判断(RewardBench v2)
Skywork-Reward-V2在PPE Correctness下五个子集的Best-of-N任务中皆达到最佳
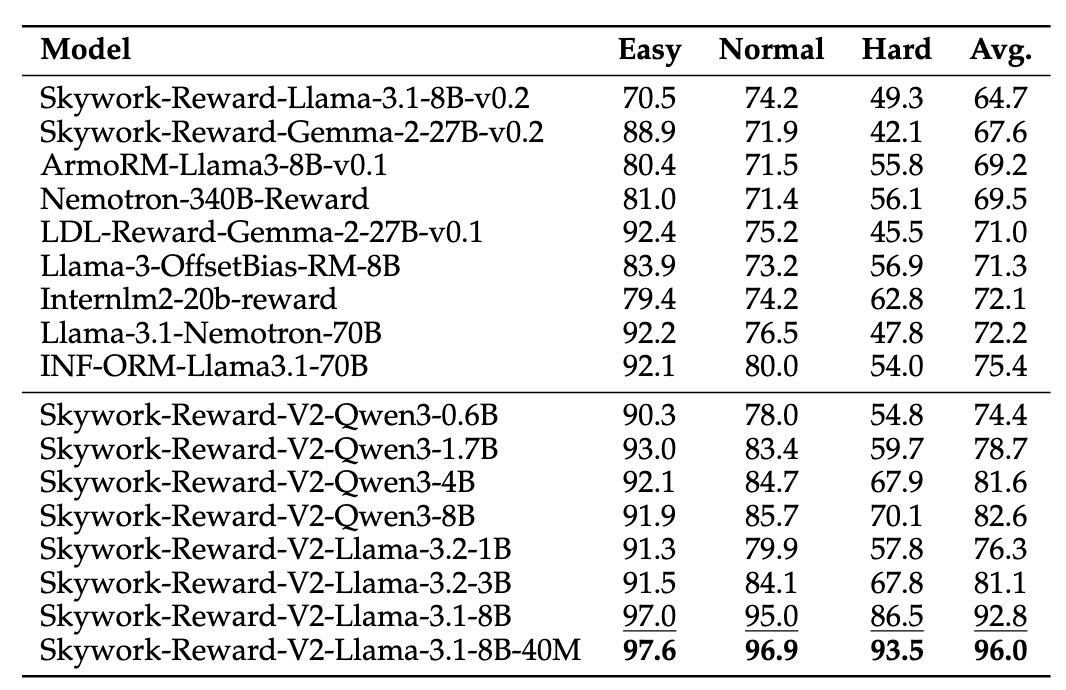
在难度较高、专注评估模型对风格偏好的抗性的RM-Bench上,Skywork-Reward-V2系列也取得了SOTA
刷新SOTA
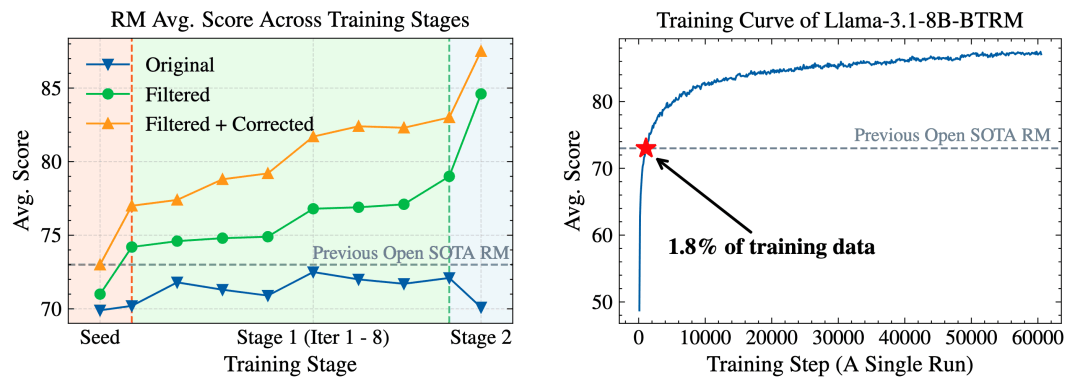
除了在性能评估中表现优异,Skywork还发现,在「人机协同、两阶段迭代」的数据构建流程中,经过精细筛选和过滤的偏好数据,会让模型变得更加聪明。
这些「精挑细选」的数据在多轮迭代训练中能够持续有效地提升奖励模型的整体性能,尤其是在第二阶段的全自动数据扩展中表现尤为显著。
相比之下,若仅盲目地扩充原始数据,非但无法提升初始性能,反而可能引入噪声,带来负面影响。
为进一步验证数据质量的关键作用,Skywork在早期版本的1600万条数据子集上进行实验,结果显示,仅使用其中1.8%(约29万条)的高质量数据训练一个8B规模模型,其性能就已超过当前的70B级SOTA奖励模型。
这一结果再次印证了Skywork-SynPref数据集不仅在规模上处于领先地位,更在数据质量方面具有显著优势。
除了模型,还有真正的AGI理想
随着技术演进与范式转变,奖励模型及其塑造机制,正快速演化为——甚至可说是唯一的——LLM训练流程中的关键引擎。
而Skywork-Reward-V2的诞生,也将推动开源奖励模型的发展,并更广泛地促进了基于人类反馈强化学习(RLHF)研究的进步。
面向未来,奖励模型——或者更广义的统一奖励系统——将成为AI基础设施的核心。
RM将不只是行为评估器,而是智能系统穿越复杂现实的「指南针」,持续对齐人类价值,驱动AI向更高阶、更有意义的方向进化。
而在这款Skywork-Reward-V2模型的背后,是已经完成「算力基础设施—大模型算法—AI应用」全产业链布局的昆仑万维。
在AI应用落地方面,他们打造了众多的AI智能体、AI短剧、和AI世界模型。
而最近备受关注的,既可以写文档、做PPT、编表格,还能一键生成网页和播客,堪称打工人的绝对利器。
同时,他们也在矢志不渝的追求AGI进步,深入模型的底层技术,探索AGI的核心逻辑。
不仅在推进AI基础智能的进步方面,

而且还在空间智能领域推出了能生成虚拟世界,更让你成为世界主宰的交互式创世引擎,和,单张图即可以生3D世界。
此外昆仑万维也始终致力于开源社区的构建,通过开放权重、技术报告、代码仓库,全球开发者、研究人员能够站在巨人肩膀上,加速AGI的迭代。
不论是面向用户的AI应用,还是探索AGI的底层技术积累,昆仑万维的使命都是:实现通用人工智能,让每个人更好地塑造和表达自我。
参考资料:
https://arxiv.org/abs/2507.01352
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






