


四倍,AI 医生的诊断准确率远超过人类医生。
这可能有点难以置信,但微软人工智能团队日前发布的一项 AI 诊断协调系统 MAI-DxO(MAI Diagnostic Orchestrator)真的做到了。
它在《新英格兰医学杂志》每周发布共计 304 个真实复杂病例上进行了基准测试。测试结果显示,准确率达到了85.5%。
这个基准测试不再是之前光凭借记忆,就可以做到的试卷答题,而是微软创建的全新的评测标准,「顺序诊断基准」(SD Bench)。它高度还原了真实诊疗过程的互动挑战:
- 从患者的初步症状描述入手。
- 通过多轮提问,选择各种检验检查,逐步手机病情信息。
- 每开一项检查,同时记录检查项目的费用;评估必要性和成本。
- 给出最终诊断。
同样面对这个 304 个复杂病例,微软选择了另外 21 位来自美国和英国,具有 5 年至 20 年临床经验的执业医生,测试结果显示,真实医生的平均准确率仅为 20%,这与 「AI 医生」的差距足足有四倍之大。
同时,与人类医生相比,这个「AI 医生」还少开了很多不必要的检查,减少了 20%-70% 的诊断成本。
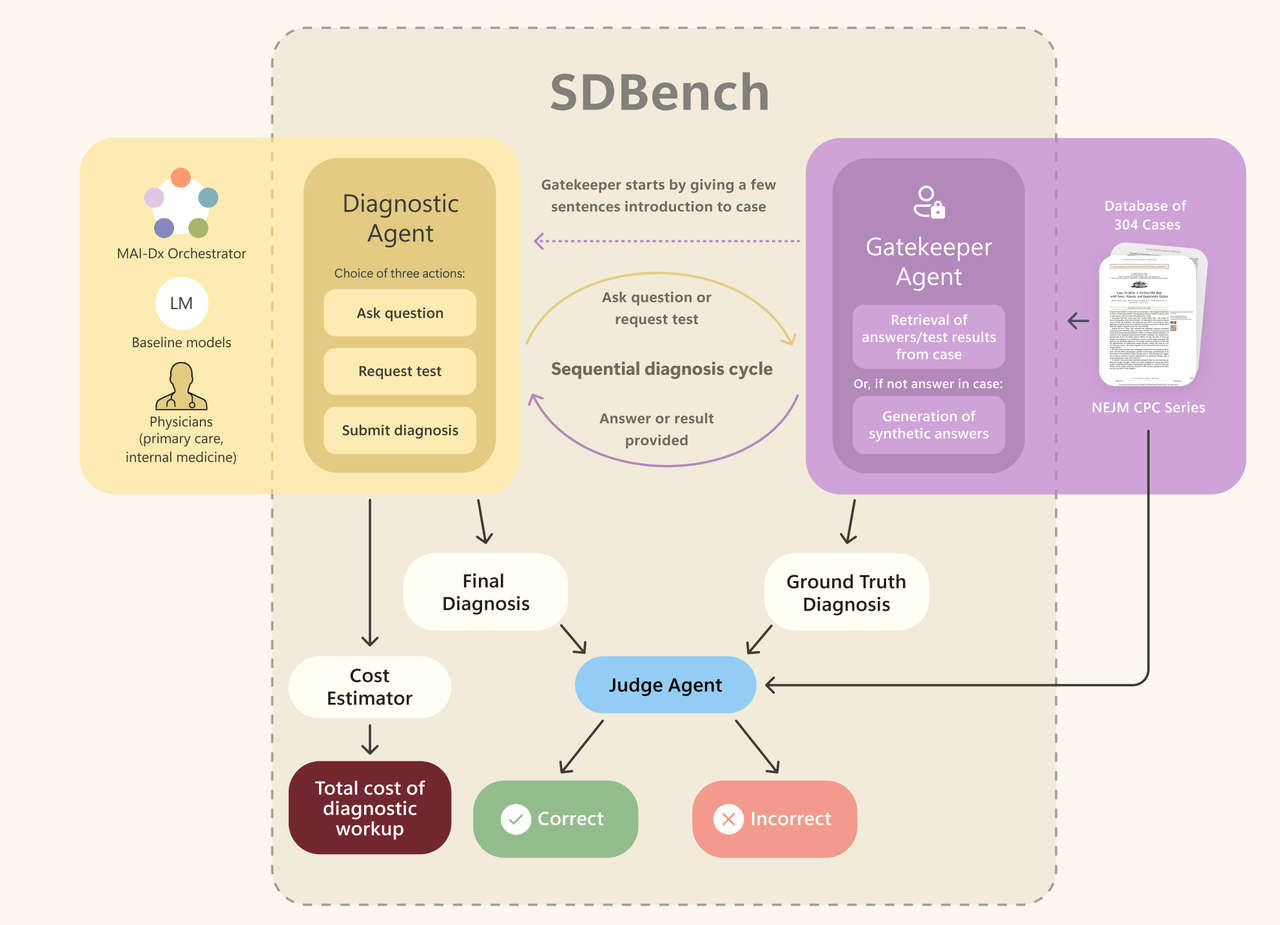
▲顺序诊断基准测试介绍图,「守门人」回应来自诊断代理的信息请求,评估模型则评估诊断代理的最终诊断与病例报告准确度。
MAI-DxO 究竟是如何做到人类医生的准确率四倍之高呢,它不是一个新出现的大语言模型,它也不依赖某个单一的模型。
MAI-DxO 是一个模拟现实中多名医生合作诊断过程的系统。得益于当前大语言模型的持续发展,在 MAI-DxO 系统中,有不同的语言模型去扮演五种不同的医疗角色。
这些医疗角色包括推测各种结果的假设医生、选择医生、质疑当前诊断假设的挑战医生、避免不必要检查的成本管理医生、以及确保诊断步骤和选择逻辑一致的检查表医生。
这些「医生」协作工作,充分地模拟了人类医生团队的工作流程,还弥补了单一 AI 模型在复杂诊断中可能出现的缺陷。
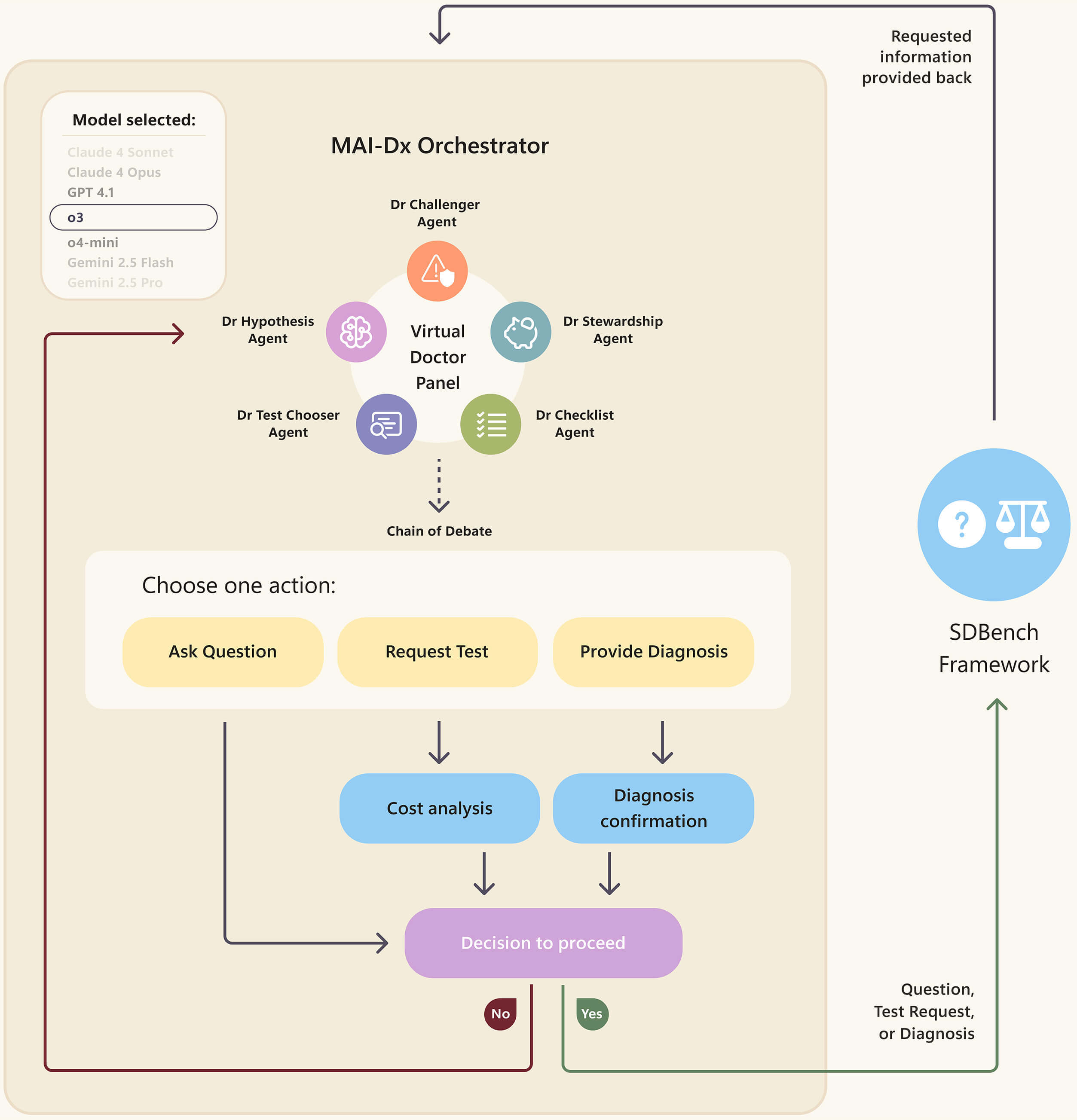
▲MAI-DxO 系统概览图
如上图描述的系统概览图所示,MAI-DxO 完全模拟了我们去医院看病的流程。
- 首先从问诊开始,MAIN-DxO 会得到一个简短的临床小故事,通常为 2-3 句话,包含病例的基本情况。
- 接着,MAI-DxO 会开始总结患者的主要诉求,选择下一步操作,是继续向患者提问,还是申请开检查。
- 每开一项检查会计算检查费用,同时持续进行多轮互动,直到给出最后诊断结果。
在测试过程中,MAI-DxO 利用 o4-mini 和专业医生设置了一个「守门人」,确保系统给 AI 的信息是与正常医生在问诊和临床上能够得到的信息一样。
MAI-DxO 的出现,为大语言模型在医疗诊断上取得明显的性能提升。微软测试了来自 OpenAI、Gemini、Claude、Grok、DeepSeek 以及 Llama 系列的不同模型,表现均优于仅使用单一的 AI 模型,而表现最好的组合是 MAI-DxO 与 OpenAI 的 o3 配对。
由于不受大语言模型的限制,MAI-DxO 还能够在将来有更好的模型出现时,同步适配。
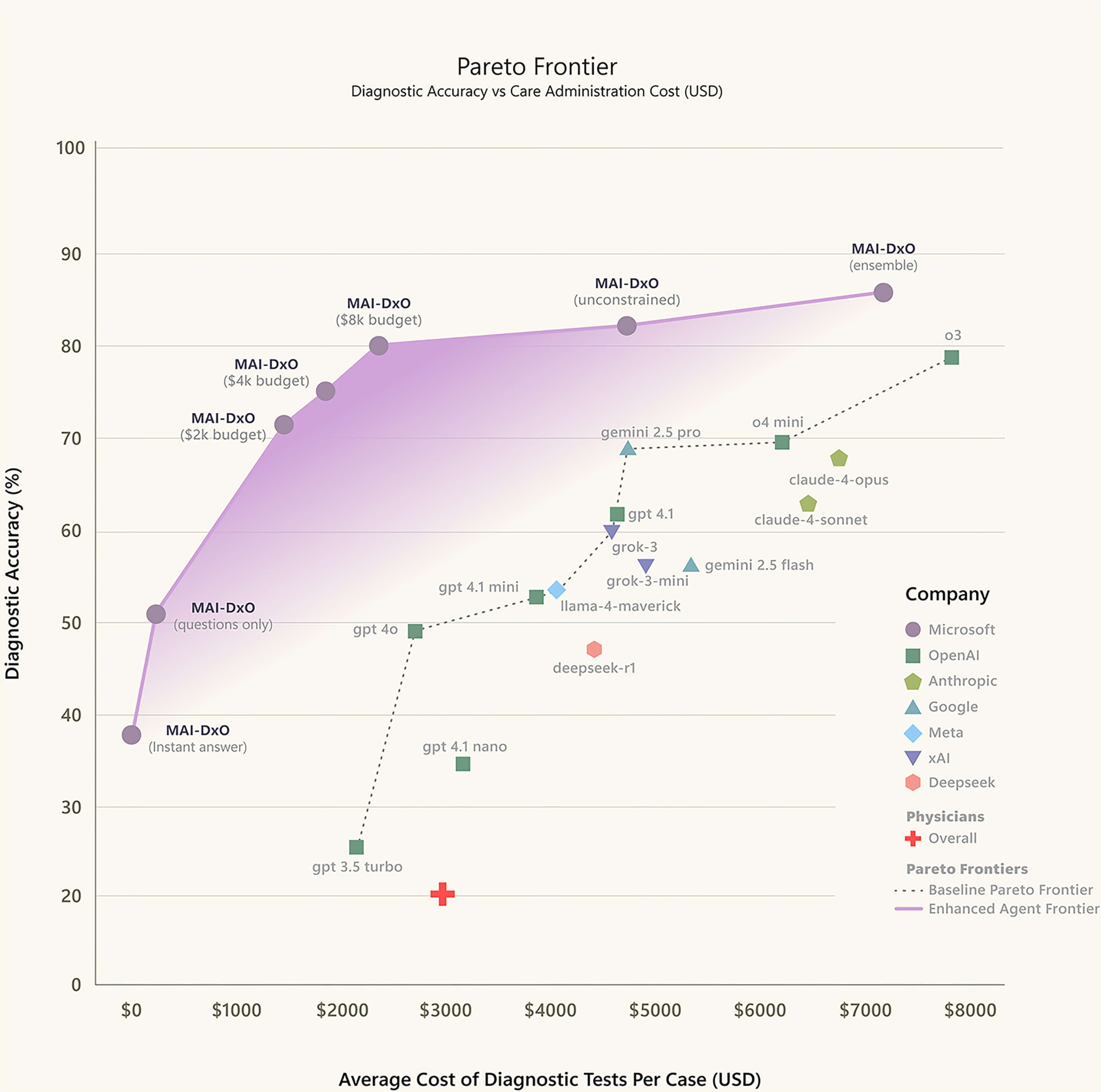
▲不同人工智能模型的准确性和每例平均诊断测试成本对比
尽管看起来 「AI 医生」已经有模有样,不过 AI 要真正做一个好医生可不是那么容易的。
微软在该项目论文最后提到,这次的研究存在显著局限性,包括像参与对比实验的 21 位医生并没有获得同行的讨论协助、参考书籍以及生成式 AI 等资源。此外,微软这次实验也仅仅只讨论了最具挑战性的病例难题,而对我们一般的日常性疾病诊断没有做进一步的测试。
微软强调 AI 不会取代医生,它将成为医生与患者共同的助手。
但就是这个医生和患者共同的助手,也持续地吸引着全世界范围的关注;早在今年 3 月,微软就发布了医疗界首个用于临床工作流程的 AI 助手 Microsoft Dragon Copilot,它能帮助医生更好的整理病例的临床文件。
IBM 推出 IBM Watson Health 医疗人工智能平台、谷歌的 DeepMind、以及英伟达的 NVIDIA Clara 等,都正从导诊、问诊、病理等医疗场景中带来新的变革。
前段时间,阿里达摩院也发布了全球首个胃癌影像筛查 AI 模型 DAMO GRAPE,首次利用平扫 CT 影像结合深度学习识别早期胃癌病灶。
华为今年才组建组建医疗卫生军团,上周也联合瑞金医院,宣布开源 RuiPath 病理模型,具备临床验证能力,覆盖肺癌等 7 个常见癌种。
医学需要极高的精准度,0.01% 的失误也有可能造成严重的后果,它完全不同于程序员写代码时出现的 bug。
MAI-DxO 模拟真实问诊的过程,看起来这条 AI 医疗之路越来越清晰。
从百度问诊,到 ChatGPT 问诊,我想未来除了拿着普通医院的检查结果,查医院排行榜,付费问在线医生,还可以先看看这个「AI 医生」。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






