


智东西
作者 | 李水青
编辑 | 云鹏
智东西6月30日报道,今日,华为首个开源大模型来了。70亿个参数的稠密模型“盘古Embedded 7B”、720亿个参数的混合专家模型“盘古Pro MoE”以及基于昇腾的模型推理技术,今日一齐开源。
基于4000颗昇腾NPU并行训练,激活参数量16B的盘古Pro MoE在MMLU、C-Eval、GSM8K等多种基准测试中,性能超越Qwen3-32B、GLM-Z1-32B等主流开源模型。其在昇腾800I A2上单卡推理吞吐性能可达1528 tokens/s,显著优于同等规模的320亿和720亿个参数的稠密模型。
目前,盘古Pro MoE 72B模型权重、基础推理码,以及基于昇腾的超大规模MoE模型推理代码,已正式上线开源平台。

▲盘古Pro MoE以及基于昇腾的模型推理技术的报告截图
技术报告地址:
https://arxiv.org/abs/2505.21411
模型下载地址:
https://gitcode.com/ascend-tribe/pangu-pro-moe-model
针对昇腾硬件优化的推理代码地址:
https://gitcode.com/ascend-tribe/ascend-inference-system
盘古Embedded 7B模型是一个引入“快思考”和“慢思考”双系统,简单问题用快速模式响应,复杂问题用深度模式推理,可自动切换。在数学、编程等多个基准测试中,盘古Embedded 7B性能超过了类似规模的Qwen3-8B、GLM4-9B等模型。
盘古7B相关模型权重与推理代码将于近期上线开源平台。

▲盘古Embedded 7B技术报告截图
技术报告地址:
https://arxiv.org/abs/2505.22375
此外,自5月19日起,华为分享了基于昇腾打造超大规模MoE模型推理部署最佳实践的技术报告,而从6月30日开始,这些技术报告相关的代码也会陆续开源出来。
一、盘古Pro MoE:基于昇腾NPU,16B激活参数比肩Qwen3-32B
混合专家模型(MoE)在大语言模型中逐渐兴起,但不同专家的激活频率在实际部署中存在严重的不均衡问题,导致系统效率低下。
为此,华为提出了如下新型的分组混合专家模型(Mixture of Grouped Experts, MoGE),它在专家选择阶段对专家进行分组,并约束token在每个组内激活等量专家,从而实现专家负载均衡,显著提升模型在昇腾平台的部署效率。
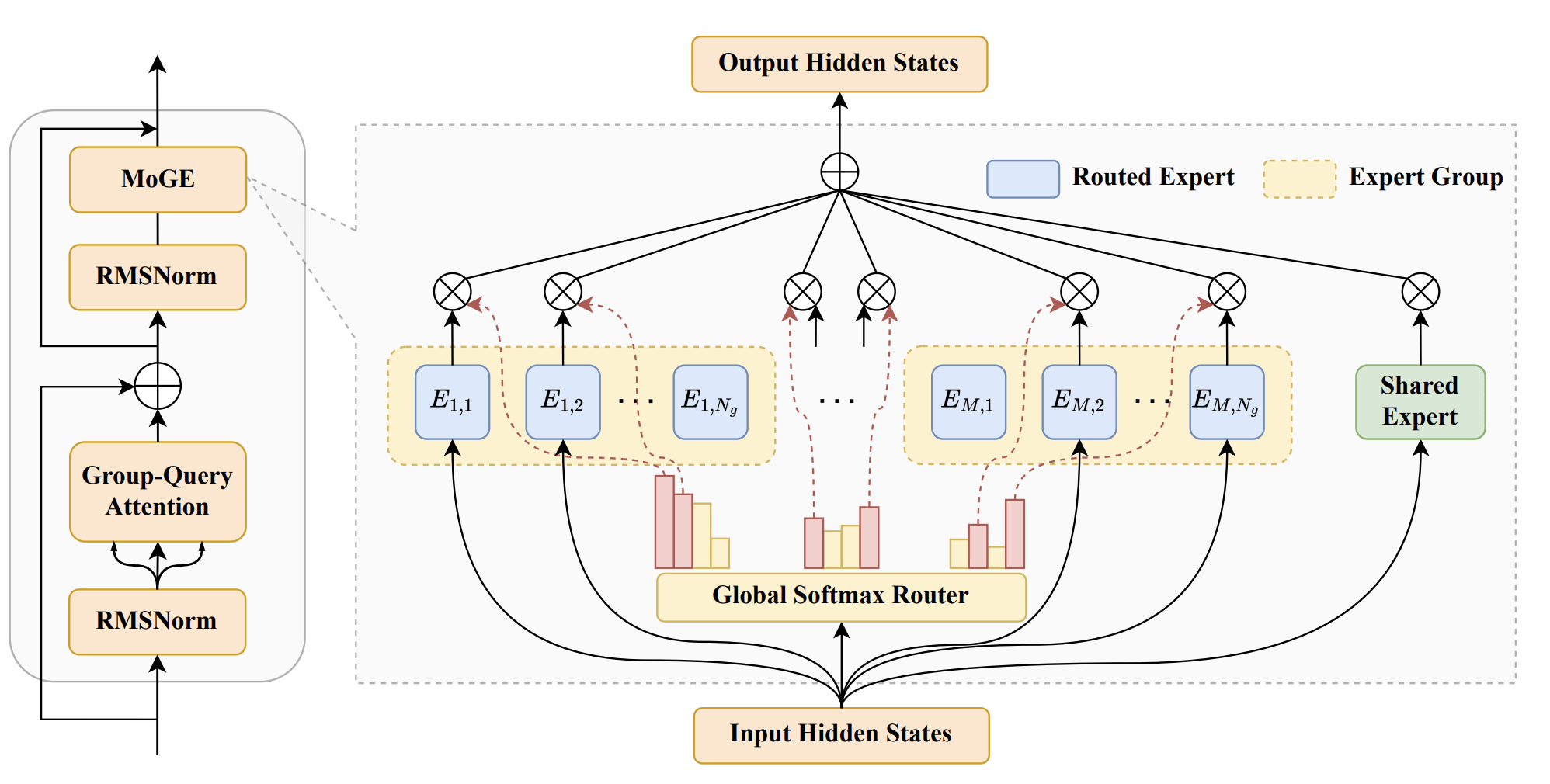
当模型执行分布在多个设备上时,这对于具有数百亿个参数的模型来说是必需的,MoGE架构设计可确保跨设备平衡的计算负载,从而显著提高吞吐量,尤其是在推理阶段。
基于MoGE架构,华为构建了总参数量720亿、激活参数量160亿的稀疏模型盘古Pro MoE模型,并针对昇腾300I Duo和800I A2平台进行系统优化。
在预训练阶段,华为使用了4000个昇腾NPU,在包含13万亿tokens的高质量语料库上进行预训练,分为通用、推理和退火三个阶段,逐步提升模型能力。
在后训练阶段,其通过监督微调(SFT)和强化学习(RL)进一步增强推理能力,还采用了检查点合并等技术优化模型。
最终,盘古Pro MoE在昇腾800I A2上实现了单卡1148 tokens/s的推理吞吐性能,并可进一步通过投机加速等技术提升至1528 tokens/s,显著优于同等规模的320亿和720亿个参数的稠密模型;在昇腾300I Duo推理服务器上,华为也实现了极具性价比的模型推理方案。
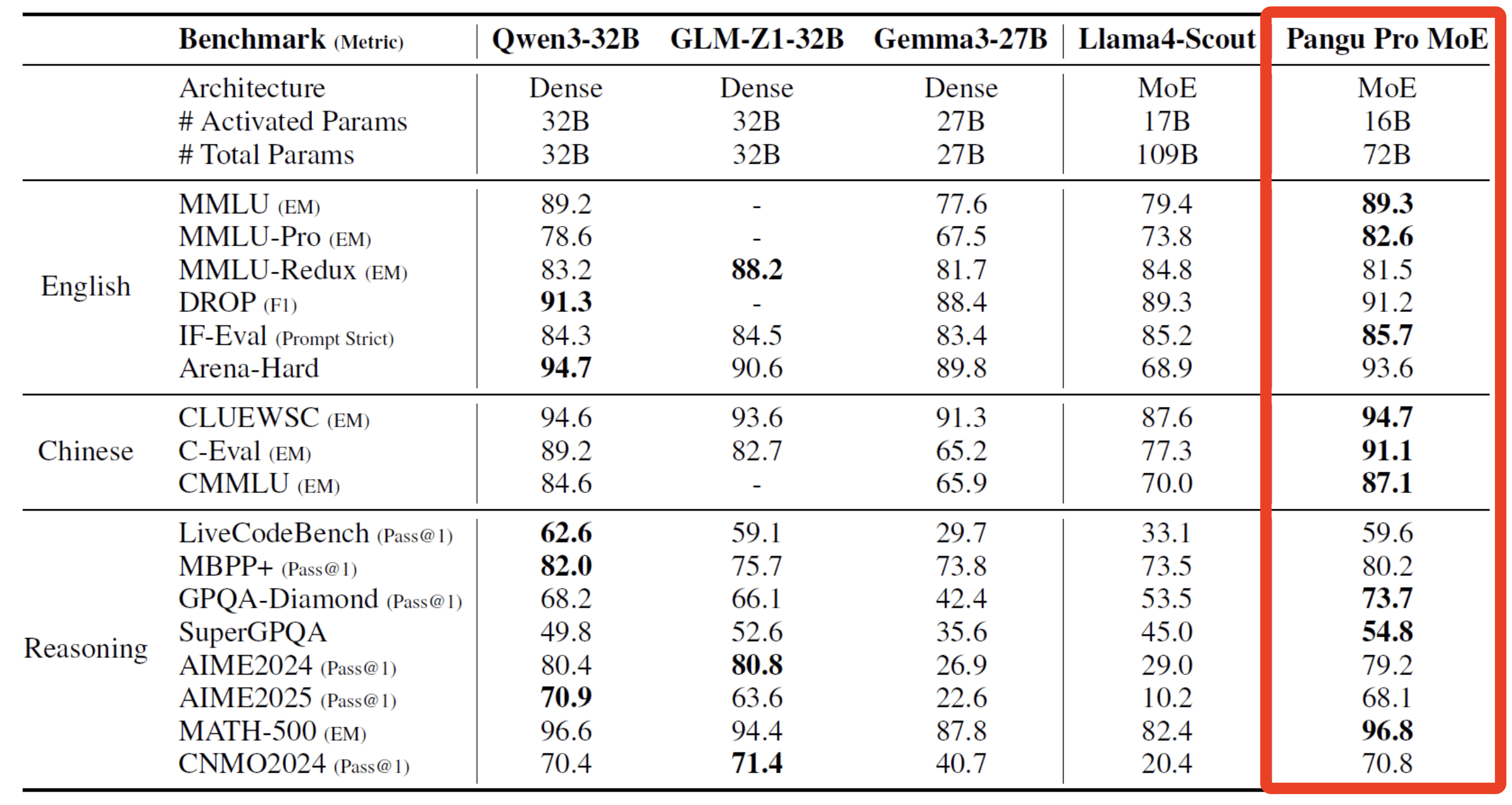
华为的研究表明,昇腾NPU能够支持盘古Pro MoE的大规模并行训练。多项公开基准测试结果表明,盘古Pro MoE在千亿内总参数模型中处于领先地位。
如下图所示,盘古Pro MoE在英语、中文及推理领域的多项能力测试中全面超越Gemma3-27B、Llama4-scout。在MMLU、C-Eval、GSM8K等多种基准测试中,盘古Pro MoE性能超越GLM-Z1-32B、Qwen3-32B等主流开源模型,展现了在多语言理解、推理等方面的领先能力。
二、盘古Embedded 7B:创新快慢思考双架构,测评超Qwen3-8B
当前,大语言模型普遍面临着巨大的计算成本和推理延迟挑战,这限制了它们的实际应用与部署。为此,华为推出盘古Embedded,一个在昇腾NPU上开发的开发的高效大语言模型推理器。
盘古Embedded的核心是一个具备“快思慢想”(fast and slow thinking)能力的双系统框架。该框架通过一个用于常规请求的“快思考”模式和一个用于复杂推理的“慢思考”模式,在延迟和推理深度之间实现了精妙的平衡。
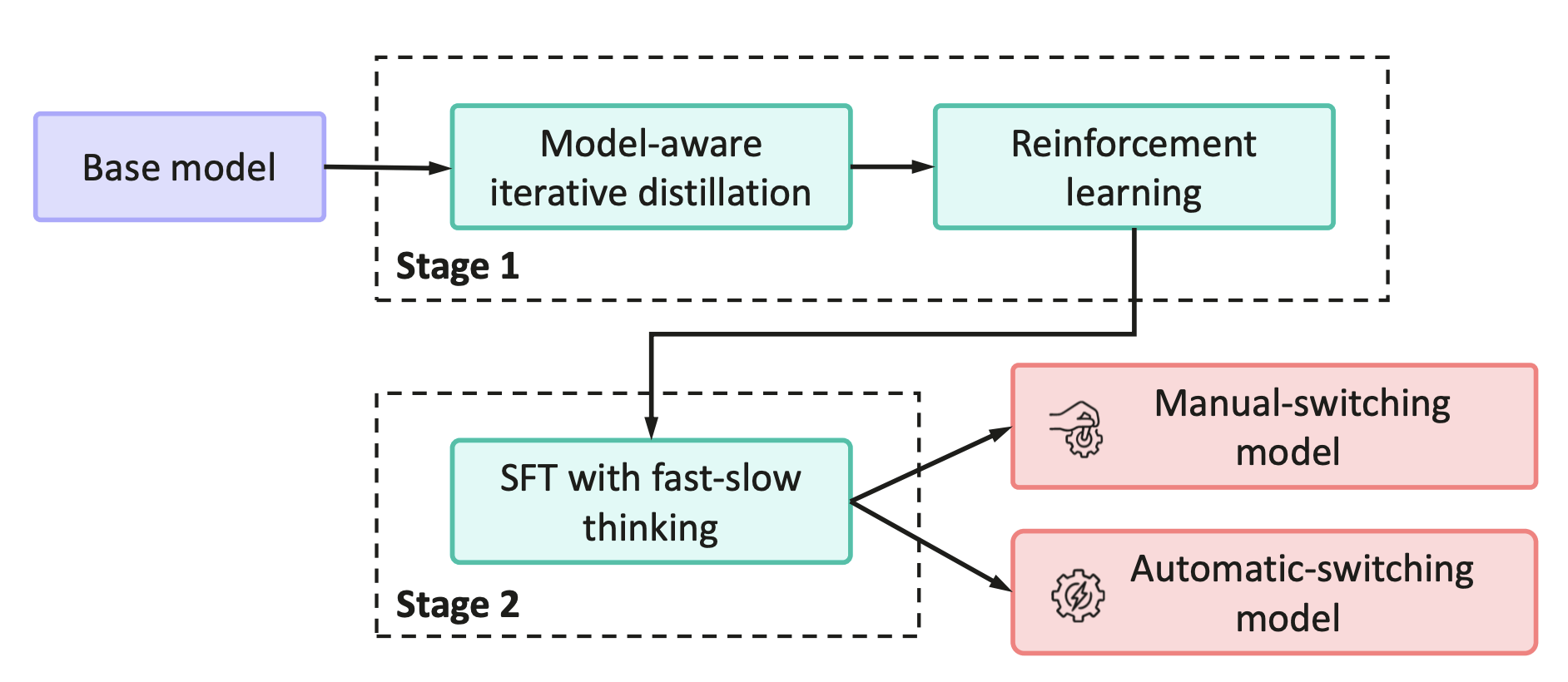
此外,模型具备元认知能力,能够根据任务复杂度自动选择最优模式。华为通过一个创新的两阶段训练框架构建此模型,该框架融合了迭代蒸馏、模型合并以及由多源自适应奖励系统(MARS)引导的强化学习。
下图是Pangu Embedded训练管道的示意图。该管道包括两个主要阶段:第1阶段是基本推理器构建,第2阶段是在一个模型中实现快速和慢速思考。
基于该双系统框架,华为构建了盘古Embedded 7B模型,并在昇腾NPU平台上进行了深度系统优化。该模型在单一、统一的架构内实现了快速响应和高质量推理的灵活切换。
研究表明,仅有70亿个参数的盘古Embedded在AIME、GPQA等多个权威的复杂推理基准测试中,表现优于Qwen3-8B和GLM4-9B等规模相近的业界领先模型。这项工作展示了一条充满前景的技术路线:在保证模型推理能力达到业界顶尖水平的同时,实现其实用化、高效率的部署。

结语:基于自研昇腾NPU,创新大模型架构
华为在大模型领域的成果进展正在加快。此前6月20日,华为推出盘古大模型5.5系列五大基础模型,并推出医学、金融等五大盘古行业思考大模型;仅仅十天之后,华为又开源两款大模型。
盘古Pro MoE通过MoGE架构与昇腾NPU的协同设计,实现了高效的稀疏大语言模型训练与推理;盘古Embedded 7B则具备灵活切换快慢思考的能力,是大模型架构设计的创新。
此举是华为践行昇腾生态战略的又一关键举措,有望推动大模型技术的发展,也正改变大模型产业的开源格局。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






